
Statistical genetics for all occasions
The recently-published memo (full text can be found at the end of this article) from a Google employee about the causes of gender disparity in the number of people working at the company generated a lively discussion. The arguments are as wide-ranging as the original post and involve many important topics. Given my area of expertise, I want to focus on a fairly narrow but fundamental part of the case made by the memo’s author. He summarizes it as follows:
Differences in distributions of traits between men and women may in part explain why we don’t have 50% representation of women in tech and leadership.
I think it is fair to say that essentially everything else in the Google diversity memo flows from this assertion. Before we begin examining it, let us lay down some groundwork.
To fix ideas, I start with a somewhat abstract and simple situation. Suppose we have two populations (call them A and B) that, on average, differ in some characteristic. While there is a real difference between means, each population consists of non-identical individuals, and so there are some distributions around the means. These distributions overlap substantially. I illustrate this scenario in the graph below (long vertical lines are the means).
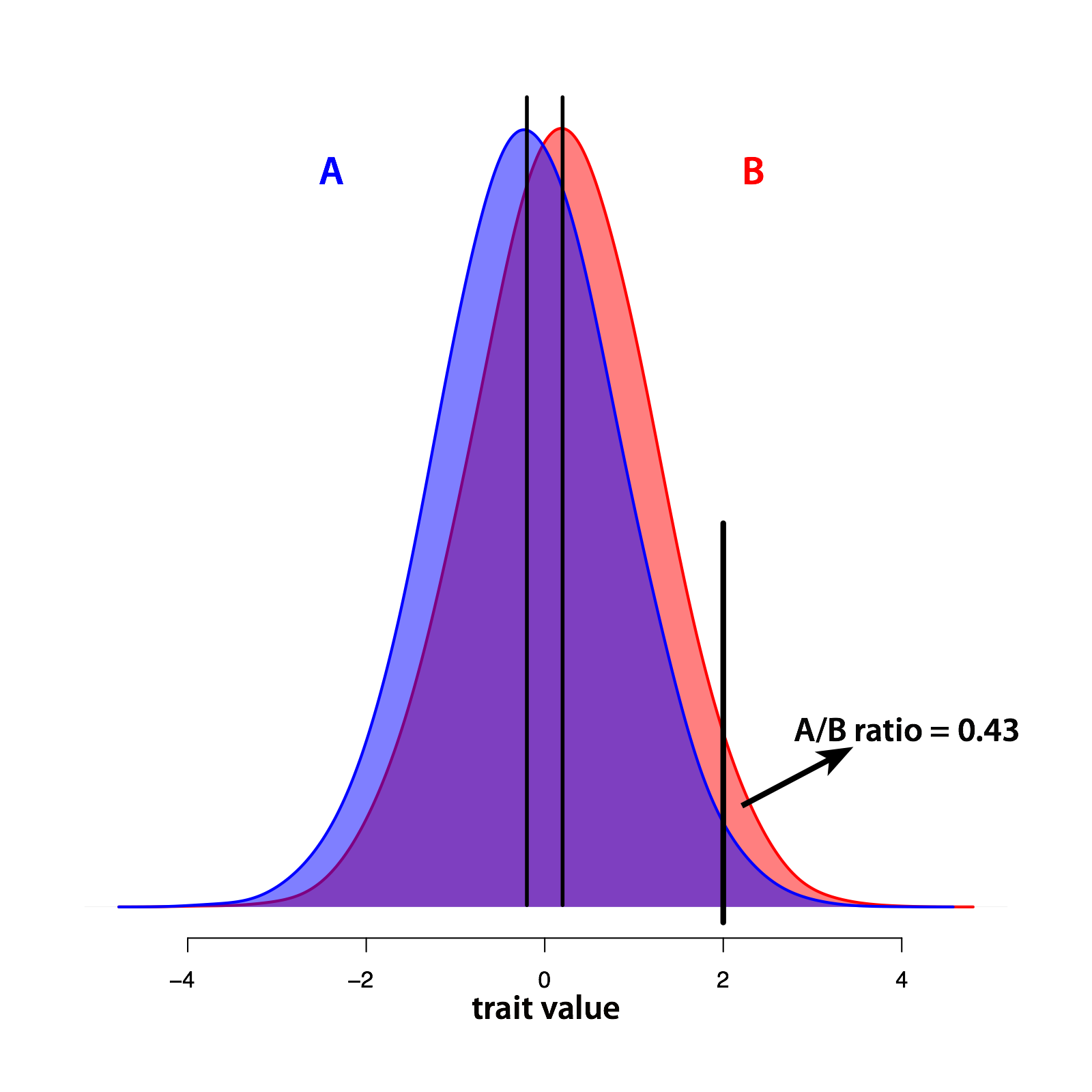
Now suppose we are looking for people to hire and we need them to score 2 or above on this nameless attribute. Assume further that we can exactly determine each person’s score. We can then screen members of both groups and select everyone who passes our test. If each group is equally represented in the applicant pool, the chosen population will have more people from group B than from group A (in the plotted example the A/B ratio is 0.43). Given all this, would we be justified in only considering individuals from group B for employment? I would argue no. The reason is simple: there are people who belong to group A and are qualified under our test. It is unfair to exclude them by disregarding their personal characteristics. Ignoring individuality in favor of group labeling is pretty much the definition of discrimination. While this is a value judgment and may not be universal, our society clearly accepts it, to the point where it is codified in law. In fact, the Google memo author emphasizes that he agrees with it:
He, instead, argues that while we cannot use group labels to discriminate against individuals, a disparity in group representation does not imply bias. This is because, as we see from our toy example, even when we screen applicants fairly and precisely, group A is underrepresented in the resulting pool of successful candidates. Since a dearth of people from minority groups in organizations is almost universally used as a measure of discrimination, this argument would seem to undermine one of very few (if not the only) quantitative measure of bias we have. The Google employee’s memo is not the first to raise this problem. Larry Summers, then Harvard president, got in no small amount of hot water more than a decade ago for presenting a similar argument. The only difference is that he chose to highlight between-population differences in variance rather than mean.
On the face of it, this seems like a compelling argument. It would appear that my model also supports it. But dig a bit deeper and we start running into problems. The crucial simplification that makes our theoretical exercise work is that groups A and B are defined by the very characteristic we wish to assess for employment suitability. This is emphatically not the case when the groups are defined by the shape of their genitalia or the color of their skin. These attributes are not directly relevant to most occupations, certainly not software engineering. Rather, we are told that group traits are associated with mental abilities that in turn predict success in engineering or some other desirable occupation. The absurdity of this position can be illustrated if instead of gender identity we group people by, say, the size of their pinky toe. We would demand that anyone asserting a relationship between such a trait and aptitude in writing computer code provide convincing evidence of an association. A long history of systematically propagated bias is the only reason gender and race are not met with the same level of skepticism when offered as group identifiers that supposedly predict skill at particular tasks. Of course, there are actually reasons to believe that, for example, gender is not inherently a good predictor of talent in STEM fields. But in any case the burden of proof is on the person arguing that gender identity predicts job performance. The Google employee’s memo provides no such evidence and is essentially a somewhat long-winded exercise in begging the question.
Measures of minority underrepresentation in workplaces and whole fields have an important role to play in assessment of discrimination. Naturally, these assessments have to be done carefully and used thoughtfully in conjunction with other data. But they should not be disregarded.